Debugging Spree
Spree is the most popular e-commerce platform built on Ruby on Rails. It’s made up of a set of different gems implementing different functions of the platform: a front and back end, an API, command-line tools and a core powering a cart and payment system.

Spree: e-commerce solution for Ruby on Rails
Until recently although I had heard of it, I’d never had the chance to deploy an application with Spree, let alone dig into its internals.
That all changed with my new job at Degica, where Spree is a core element of almost everything we do. Not only do we use Spree to power our carts, we’ve also extended it, built on it, transformed it and twisted it to make it do things it was probably never intended to do.
Putting aside the question of whether this kind of “adaptation” is a good thing (and you could fairly argue that in some cases it is not), as a programmer it presents an interesting challenge: to ensure that the core Spree engine and everything we’ve built on top of it are working smoothly together. The more complex our adaptations become, the more difficult this can be.
One bug we hit on recently brought this challenge home to me, and got me thinking about the whole process of programming and how it is affected by our environment.
A transaction in limbo
The bug was brought to our attention by our customer support team, who reported that some customers would make an order, get a confirmation email with payment instructions, pay for the product, but then never receive the expected license key(s) from us.
When we checked our system, we saw that the payment attached to the order was in
a “failed” state. Spree’s cart makes extensive use of the
state_machine gem to manage
transitions between
the sequence of events in the cart checkout and payment process. The “failed”
state in this machine is a final state with no transitions – once payment
reached this state, the order was effectively killed on our side.
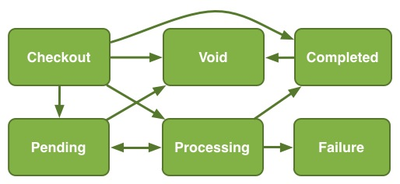
Transitions between payment states in the Spree payment flow
The mystery deepened when we checked with the gateway and learned that, while the order had failed on our side, the payment had gone through on theirs without any issues. Customer support made a note of the bug on the order and manually triggered delivery of the keys as we began the process of combing our logs to figure out what had happened.
Eventually we tracked the problem down to “double submission” by the client: for whatever reason (perhaps an accidental double-click or javascript bug), the customer sent two requests to our server with the same order number. Since our servers run multiple workers (unicorns), each request triggered a parallel request to the payment gateway with the same information.
The gateway accepted the first request, returning a success response and triggering our system to send out the first confirmation email and mark payment as “pending”. But when the second request hit the gateway, it returned an error complaining that the payment had already been processed. This in turn caused the second worker to overwrite the previous pending state with a “failed” state.
Through this sequence of events, the order was left in limbo: its payment had been accepted by the gateway but marked as failed on our system, so it was unable to transition to the “complete” state and deliver the requested keys.
The ghost in the (state) machine
At this point, based on log data and a bit of guesswork, we had narrowed down
the what of the bug, but not the why. I found that
I could actually reproduce the bug running multiple unicorns on my laptop, but
the deep integration of the state_machine gem into Spree – not to mention the
commits we had added in our fork
– made it hard to pinpoint where the bug was actually coming from.
The Spree
documentation described
a “payment processing” state, “intended to prevent double submission” (see
diagram above). The
state is triggered by the started_processing method, which is
called in two key places: in the
authorize!
and
purchase!
methods of the Spree::Payment::Processing module, included in
Spree::Payment. Payment processing is wrapped in the process! method in a
conditional
which checks that it is not already in that state – this is the mechanism to
prevent double submission mentioned in the documentation.
The conditional should block double submission, but when I dug deep enough, I found
that this was not happening.
By placing a binding.pry call in the authorize!
method, I could get two parallel processes simultaneously into the processing
state, which by all accounts should not be possible.
Running slower through the code with parallel pry sessions, I found that
although the first process would see the payment state as processing, the
second process would see it as pending until it too entered the processing
state. With both processes processing, I
then opened a mysql session and found that – contrary to what both pry
sessions were telling me – the state in the database was still pending.
The processes, in other words, were running in bubbles. Or, in database-speak, “transactions”.
Transactions in transactions
A transaction is a unit of work performed in a database which can be rolled-back at any point prior to completion. Two processes running in transactions are isolated until the point when the transaction ends and data is written to the database.
A quick check from either pry session confirmed that the payment processing code was indeed wrapped in a transaction:
ActiveRecord::Base.connection.open_transactions #=> 1
Before moving on, I wrote a quick failing test isolate the problem:
it "does not process payment within transaction" do # Make sure we are not already in a transaction ActiveRecord::Base.connection.open_transactions.should == 0 Spree::Payment.any_instance.should_receive(:authorize!) do ActiveRecord::Base.connection.open_transactions.should == 0 end order.payments.create!({ :amount => order.outstanding_balance, :payment_method => payment_method, :source => creditcard}) order.next! end
Now all I had to do was get this test to pass. To do this, I had to dig into
state_machine, particularly the
1.1.2 release which Spree 1-3-stable uses.
As it turns out, there are some inline
comments
that were a big help:
# To turn off transactions: # # class Vehicle < ActiveRecord::Base # state_machine :initial => :parked, :use_transactions => false do # ... # end # end # # If using the +save+ action for the machine, this option will be ignored as # the transaction will be created by ActiveRecord within +save+. To avoid # this, use a different action like so: # # class Vehicle < ActiveRecord::Base # state_machine :initial => :parked, :use_transactions => false, :action => :save_state do # ... # end # # alias_method :save_state, :save # end
So here was my answer: add the :use_transactions => false and :action =>
:save_state options and alias save to save_state. (The
details of why we have to alias save to save_state are pretty involved,
but the basic point is that state_machine runs its transition callbacks
as ActiveRecord callbacks if the action is save, and these callbacks are
called within the transaction. State transition callbacks on any other
action are run around the action, so are not within the transaction.)
With these small changes, my test passed and the processing state actually
began to do its job. I’m happy to say that those changes have now been
incorporated into the master (PR)
and 1-3-stable (PR) branches of
Spree, and I can count myself as one of the contributors to the project.
(Thanks in particular to @huoxito who read and
responded to my rambling
comments on
the pull request.)
Epilogue
This little “bug hunting” expedition was quite an eye-opening experience for me. The bug itself of course taught me a lot about the internals of Spree. More than that, though, it highlighted to me how essential it is that programmers have the space and freedom to dive deep into code – as deep as necessary – to solve difficult, often unexpected problems.
Here is a case where a silently failing feature in the core of a widely-used library emerges as an annoying double-click bug, one that could easily be ignored or patched at the surface level. To actually fix the bug required the patience to yank it out by its roots, delving through application code, to a dependency on a forked core library (spree), to the interaction of that library with its own dependency (state machine).
At any point, it would be very easy for something (an impatient manager, impending deadline or unexpected event) to interrupt the bug hunt and leave the core library broken. No disaster would have resulted had that happened in this case, and I could have spared myself days of frustrating debugging.
But in the long run, this would leave us with a broken payment system at the core of all our e-commerce applications. If anyone underestimated the importance of having reliable open-source libraries, recent events have provided ample evidence to convince them otherwise.
Disregarding the bug would also have left me, the programmer, with a gaping hole in my understanding. It would have robbed me of a great chance to understand how the system works. And it would have left me with the disempowering sense that the bug was beyond my understanding, when in fact it was not.
I’m glad that didn’t happen to me in this case. But I have to wonder how often it does, and how that type of failure – coming back empty-handed after hours or even days of fruitless bug hunting – must affect programmers and the code they write. The experience has given me a greater appreciation of how much a work environment can contribute to code quality. And it has taught me to slow down: to look at problems carefully before rushing in to solve them, to think carefully before rushing to write code.
Here’s hoping those lessons will lead to more successful bug hunts, and less bugs.
Posted on April 17th, 2014.