The Ruby Module Builder Pattern
There’s an interesting pattern I’ve discovered recently in Ruby that is very powerful, yet apparently not widely known or appreciated.1 I call this pattern the Module Builder Pattern. I’ve used it heavily in designing Mobility, a pluggable translation framework I released a couple months ago, and it served me so well I thought I should share what I’ve learned.
At its core, the Module Builder is an extremely simple, elegant, and versatile
way of dynamically defining named, customizable modules to mix into classes.
This is done by subclassing the Module
class,
initializing these subclasses at runtime, and including the resulting modules
into other classes.
If the idea of subclassing Module makes your head spin, read on.
Despite its seemingly esoteric nature, the Module Builder does some very
useful things. It is used extensively in projects such as
dry-rb to great effect, but buried out of view among
advanced coding styles that conceal its essential simplicity. It is also used
sporadically in Rails2, but only to a very limited
extent. I think it’s fair to say that most Rubyists have never seen the
pattern, let alone ever used it in their daily work.
To explain Module Builder, I will work through a series of progressively more complex examples, ending with some code extracted from my work on Mobility into a gem called MethodFound. The examples begin with some simple core concepts I think most readers will understand, then advance to a slightly more in-depth discussion exposing the pattern’s tangible benefits in real-life applications.
Modules in Ruby
Let’s first recall that a module in Ruby is basically a collection of methods
and constants which you can include in any class, reducing duplication and
encapsulating functionality in reusable, composable3
units. Callbacks like
included
and extended
allow you to execute some custom code every time your module is
included (or extended, etc) in a class or module.
So suppose we have a module MyModule with a method foo:
module MyModule def foo "foo" end end
Now we can add this method to any class by including MyModule:
class MyClass include MyModule end a = MyClass.new a.foo #=> "foo"
That’s pretty straightforward, but also very limited: foo is pre-defined
with a hard-coded return value.
Let’s take a slightly more “real-world” case. Say we’ve got a class, Point,
with two attributes x and y, which for simplicity’s sake we’ll define
using a Struct:
Point = Struct.new(:x, :y)
Now let’s create a module which can add two points together at their
respective x and y values. Call it Addable:
module Addable def +(point) Point.new(point.x + x, point.y + y) end end Point.include Addable p1 = Point.new(1, 2) p2 = Point.new(2, 3) p1 + p2 #=> #<Point:.. @x=3, @y=5>
The module is slightly more reusable now. But it still has rigid constraints:
it will only work with a class called Point which has attributes x and
y.
We can improve this a bit by removing the constant Point in the module, and
replacing it with self.class:
module Addable def +(other) self.class.new(x + other.x, y + other.y) end end
Now our Addable module can be used with any class that has accessors x and
y,4 which makes it much more flexible. Also, thanks to
Ruby’s very dynamic treatment of types, the module can be used to “add” a
potentially wide variety of pairwise data types, as long as their elements
have a + method.
In addition, note that modules in Ruby have the property that their methods can be
composed through inclusion or inheritance by using the super keyword in
the including or parent class. So if we wanted to log calls to our adder method, we
could do this by defining + inside of the Point class, like this:
class Point < Struct.new(:x, :y) include Addable def +(other) puts "Enter Adder..." super.tap { puts "Exit Adder..." } end end
And we can see that our logging indeed works as expected, calling the method
on the class first, and then through super the method defined on the module:
p1 = Point.new(1, 2) p2 = Point.new(2, 3) p1 + p2 Enter Adder... Exit Adder... #=> #<Point:.. @x=3, @y=5>
There are many other things to say about modules; we’ve really only touched the tip of the iceberg here. However, the main topic of this post is module builders, not modules, so let’s take a look at that.
Building a Module that Builds Modules
Modules that Build
Modules are powerful because (when used effectively) they encapsulate certain
shared patterns of functionality. In the example above, this functionality is
the addition of variable pairs (points, or any other class with pairs of
variables x and y). Identifying shared patterns like this and expressing
them in the form of a module or set of modules makes it possible to tackle very
complex problems with simple, modular solutions.
That said, the module above is still quite specific, constrained to classes
with variables x and y. What if we wanted to loosen this constraint and
have the module work for any set of variables? How would we do that?
Well, a module can’t be configured once defined, so we’ll need some other way to loosen
this constraint. One way is to define a method
on the module that itself adds the desired functionality to the class. Let’s
call this method define_adder5:
module AdderDefiner def define_adder(*keys) define_method :+ do |other| self.class.new(*(keys.map { |key| send(key) + other.send(key) })) end end end
Instead of defining a + method like we did in the Addable module, we
instead define a method which defines the method. We’ll call this
“method-defining method” the bootstrap method here, since it “bootstraps”
the module’s instance methods dynamically into the class.
This bootstrap method takes an arbitrary number of arguments, mapped to an
array keys using the splat
operator.
These “keys” are the names of the variables to add (or, more precisely, the
names of the methods which return the variable values). It then defines a
method, called +, which adds the values of these variables at each key and
creates an instance from the results using self.class.new.
Let’s see if it works. We’ll create a new class, LineItem, with different
reader names, and extend the module in this case rather than include it
(since define_adder needs to be a class method):
class LineItem < Struct.new(:amount, :tax) extend AdderDefiner define_adder(:amount, :tax) end
Now we can add line item pairs, just like we did point pairs earlier:
l1 = LineItem.new(9.99, 1.50) l2 = LineItem.new(15.99, 2.40) l1 + l2 #=> #<LineItem:... @amount=25.98, @tax=3.9>
So it works! And we now have no dependency on variable names (or even on number of variables), so our module is more flexible.
But there’s a problem. When we copy over our earlier logging code from the
Point class to log calls to +, like this:
class LineItem < Struct.new(:amount, :tax) extend AdderDefiner define_adder(:amount, :tax) def +(other) puts "Enter Adder..." super.tap { puts "Exit Adder..." } end end
… and then add two line items again, instead of getting the expected logs, things blow up with an exception:
NoMethodError: super: no superclass method `+' for #<struct LineItem amount=9.99, tax=1.5>
What’s going on here?
Take a good look at how define_adder bootstraps the + method: it
uses define_method to add the method directly to the class, in this case
LineItem. A class can only have one definition of any given method, so when,
later in the class, we again define +, we clobber the earlier definition.
There is no “superclass” here since we have not included or inherited anything
when defining the method.
Solving this problem will require some “module building” magic. Let’s look at the solution first, and then see how it solves this issue:
module AdderIncluder def define_adder(*keys) adder = Module.new do define_method :+ do |other| self.class.new(*(keys.map { |key| send(key) + other.send(key) })) end end include adder end end
Now we replace AdderDefiner in the logged LineItem code above with
AdderIncluder and we find that it works:
l1 = LineItem.new(9.99, 1.50) l2 = LineItem.new(15.99, 2.40) l1 + l2 Enter Adder... Exit Adder... #=> #<LineItem:... @amount=25.98, @tax=3.9>
The trick that makes this work is the use of an anonymous module in
define_adder to define the + method, which is different from the previous
technique of defining the method directly on the calling class.
Recall that in Ruby, any module (small “m”) is simply an instance of a class,
and this class is Module (big
“M”). Like other classes, Module has a new method, in this case one which
can take a block
argument and
evaluate the block in the context of the newly-created module.
So to generate a “module on the fly”, you can simply call Module.new, pass a
block with some method definitions, and use it just as you would any other
(named) module:
mod = Module.new do def with_foo self + " with Foo" end end title = "The Ruby Module Builder Pattern" title.extend mod title.with_foo #=> "The Ruby Module Builder Pattern with Foo"
This is a handy trick, often used in testing when you don’t want to clutter
the global namespace with a one-off module used only in a single test (works
for Class too).6
The method defined in the block in AdderIncluder is the same + method
defined earlier in AdderDefiner, and in this sense, the two modules perform
a very similar function. The key difference is that whereas AdderDefiner
defines the method on the class, AdderIncluder includes a module with the
method into the class.
If you look up the chain of ancestors, you will see this module just after the
LineItem class itself:
LineItem.ancestors #=> [LineItem, #<Module:0x...>, ...
Given this ancestor chain, it is clear why super works here: when you
call + on LineItem, the method calls super, which continues up the
class hierarchy to the anonymous module where our + method is defined. It
then calculates and returns the result, which gets composed in the LineItem
adder with the logging code.
Although at first glance it might seem somewhat strange and unfamiliar, this
technique of defining a bootstrap method to include a dynamically-generated
anonymous module is in fact extremely useful, and widely used for this reason.
This is particularly true for a flexible framework like Rails, where simply
defining a model
or setting up routes
triggers calls to many bootstrap methods like define_adder. The technique
can also be found in other gems that require a similar level of flexiblity
(including Mobility).
Bootstrapped module building can thus be considered a very important metaprogramming technique in Ruby. Indeed, it underpins the very dynamic nature that enables frameworks like Rails to work the way they do.
That said, I hope to convince you here that the potential of module building goes well beyond the bootstrapping technique shown above, and as such that it is a pattern that deserves more attention. To do this, I’m going to return to the Adder module one last time, and define it in a slightly different way.
The Module Builder
So far we’ve looked at three “adder” modules:
Addable, which adds a+method on two variables x and y,AdderDefiner, which adds a class methoddefine_adderthat defines a+method on an arbitrary set of variables, andAdderIncluder, which also adds a class methoddefine_adderthat defines the+method, but in such a way that the method can be composed usingsuper.
Although not very flexible, note that in hindsight, the first Addable module
had some good things going for it:
- It only included the
+method, and left no other bootstrapping “artifacts” likedefine_adder(unlike bothAdderDefinerandAdderIncluder) - It allowed the parent class to access its methods using
super(likeAdderIncluderbut notAdderDefiner) - It had a name, and was therefore very easy to recognize in the chain of
ancestors. While
AdderDefinerandAdderIncluderthemselves appear in the chain of ancestors, the fact that the bootstrap method was called, and how it was called, is hard or impossible to discern.
In this section, I will show how we can solve the adder problem in a way that retains these benefits, while also offering the flexibility we sought in the last section.
Module Builders
Let’s start by defining an AdderBuilder class which inherits from Module:
class AdderBuilder < Module def initialize(*keys) define_method :+ do |other| self.class.new(*(keys.map { |key| send(key) + other.send(key) })) end end end
This is a short but very dense little class. Before going into the details of
what it’s doing here, let’s first check that it works. We’ll include (not
extend) an instance of this class (a module) into LineItem this time:
class LineItem < Struct.new(:amount, :tax) include AdderBuilder.new(:amount, :tax) end l1 = LineItem.new(9.99, 1.50) l2 = LineItem.new(15.99, 2.40) l1 + l2 #=> #<LineItem:... @amount=25.98, @tax=3.9>
So, as we can see, this little class does the same thing that we achieved with
the define_adder bootstrap method in AdderDefiner, except without ever
defining a class method to do it.
How does it do this? First, it subclasses Module. Since we can call new on
Module, it’s not much of a stretch to imagine
that we can also subclass it and define our own methods such as
initialize. And indeed, as shown above, we can do this.
Here’s that initializer again:
def initialize(*keys) define_method :+ do |other| self.class.new(*(keys.map { |key| send(key) + other.send(key) })) end end
There are two levels at play here, and it’s important to recognize both of
them. On one level, we are initializing a new instance of a class, Module.
This instance is itself a module, so it’s a collection of methods we will mix
into other classes. We are then, as we initialize this module, defining one
of these methods, a method called +.
The method + itself is being defined in terms of the method names we have
passed as arguments to Module.new (the “keys”, which were :amount and
:tax in the example above).7 When we call
self.class.new in the method, this new will be evaluated in the context
of the class including this new module, and thus would evaluate to LineItem
(or Point, or whatever class the module was included into).
So AdderBuilder.new(:amount, :tax) evaluates to a module
functionally equivalent to this:
Module.new do def +(other) self.class.new(amount + other.amount, tax + other.tax) end end
… which is what we had in Addable, with x and y swapped for amount
and tax. But the power here comes from the fact that we can define our
dynamic module in terms of whatever variable names we want.
And herein lies the essential ingenuity of this pattern: that it allows you to define modules not as fixed collections of methods and constants, but as configurable prototypes for building such collections. There is no need for class methods or other metaprogramming tricks to bootstrap the module-inclusion step; the builder builds modules directly, so they can be included in one step.
Not only that, but the modules created in this process, unlike the anonymous modules generated by techniques described in the last section, actually have a name, so you can clearly see them in the chain of ancestors:
LineItem.ancestors [LineItem, #<AdderBuilder:0x...>, Object, ... ]
This is a nice by-product of the encapsulation we have achieved by subclassing
Module.8 With an anonymous module, this is much harder
to debug:
LineItem.ancestors [LineItem, #<Module:0x...>, Object, ... ]
Module Builders thus have the benefits of anonymous modules (their instances can be defined “on the fly” and do not clutter the global constant namespace), are easily traceable since their instances have a name (like “normal” modules), and yet do not require defining (and calling) new methods on the including class to bootstrap them.
We can go a step further. We previously added some logging code to the
including class. This logging code can also be rewritten as a module builder,
which we will call LoggerBuilder:
class LoggerBuilder < Module def initialize(method_name, start_message: "", end_message: "") define_method method_name do |*args, &block| print start_message super(*args, &block).tap { print end_message } end end end
Now we can log any included or inherited method by creating an instance of
LoggerBuilder with the name of the method to be logged:
class LineItem < Struct.new(:amount, :tax) include AdderBuilder.new(:amount, :tax) include LoggerBuilder.new(:+, start_message: "Enter Adder...\n", end_message: "Exit Adder...\n") end
And, presto, we’ve got a logged addable line item:
l1 = LineItem.new(9.99, 1.50) l2 = LineItem.new(15.99, 2.40) l1 + l2 Enter Adder... Exit Adder... #=> #<LineItem:... @amount=25.98, @tax=3.9>
But of course, we can now also log any other included or inherited method we like:
LineItem.include(LoggerBuilder.new(:to_s, start_message: "Stringifying...\n")) l1.to_s Stringifying... => "#<struct LineItem amount=9.99, tax=1.5>"
There are many other directions you can take this; I’ve only scratched the
surface here. For a relatively simple (yet powerful) example of this “in the
wild”, take a look at Dry
Equalizer, which dynamically defines
equality methods on a class using an instance of an Equalizer class that,
like AdderBuilder, subclasses Module.
Module Builders and Composition
You may have noticed that I have used the word “compose” quite a lot in this
post with respect to including modules into a class. Any time you include a
module which overrides a method and calls super, you are in effect using
function (method) composition, although it is not generally referred to as
such.
The same is true of our logging code in the last section. When we include an
instance of both AdderBuilder and LoggerBuilder, we are building + as
a composite function, which we could alternatively write as:
class LineItem < Struct.new(:amount, :tax) def add(other) self.class.new(amount + other.amount, tax + other.tax) end def log(result) print "Enter Adder..." result.tap { print "Exit Adder..." } end def +(other) log(add(other)) end end
So super is essentially taking the output of the last method call and
incorporating it into the result of the current module’s method.
Composition happens to be a very interesting way to “combine” different instances of a module builder, like we combined logging and adding modules in the example above. With module builders, we can configure and combine many modules to build more complex methods and class behaviours.
One way to do this is via a “branching” method flow. We define multiple
modules that each override the same method, but only trigger some special
processing if a condition on the method and its arguments matches the module’s
state; otherwise, the control flow continues up the class hierarchy to the
next module via super.
If you’ve worked with Ruby for any length of time, this “branching
composition” should make you think of one method:
method_missing.
Rarely does anyone override method_missing without a call to super
somewhere, since doing so would catch any method not defined on the class, which is
generally not what you want.
Instead, a typical method_missing override looks something like this:
def method_missing(method_name, *arguments, &block) if method_name =~ METHOD_NAME_REGEX # ... do some special stuff ... else super end end
… where METHOD_NAME_REGEX is a regex used to determine if we should “do
some special stuff”.
I actually use exactly this branching flow in
Mobility in a module builder called
FallthroughAccessors.
Each instance of FallthroughAccessors is initialized with a set of
attributes (its “state”) and intercepts method calls where the method name
is made up of one of these attributes plus a locale suffix (e.g.
title_fr for the title attribute in French), which I refer to as an “I18n
accessor”. If the method name
matches, the attribute value in the suffix locale is returned,
otherwise control continues up the class hierarchy.
Composing method_missing in module builders this way results in an
sequence of nested regex conditionals spread across a series of modules, which
I call “interceptors”. The fact that these interceptors are entirely
encapsulated, with no external dependencies on the class itself, enables
Mobility to “plug in” i18n accessors for each translated attribute
independently, at any time and in complete isolation from each other.
Having found this pattern useful in Mobility, I extracted it into a gem called MethodFound. MethodFound is essentially one module builder, MethodFound::Interceptor, which intercepts method calls that match a regex or proc (the “state” in this case) and passes the method name, any matches captured in the regex (or the return value of the proc), and any method arguments to a block (the “do some special stuff” in the conditional above). This block is evaluated in the context of the instance of the class including the module.
Here’s an example:
class Greeter < Struct.new(:name) include MethodFound::Interceptor.new(/\Asay_([a-zA-Z_]+)\Z/) { |method_name, matches| "#{name} says: #{matches[1].gsub('_', ' ').capitalize}." } include MethodFound::Interceptor.new(/\Ascream_([a-zA-Z_]+)\Z/) { |method_name, matches| "#{name} screams: #{matches[1].gsub('_', ' ').capitalize}!!!" } include MethodFound::Interceptor.new(/\Aask_([a-zA-Z_]+)\Z/) { |method_name, matches| "#{name} asks: #{matches[1].gsub('_', ' ').capitalize}?" } end
Here we have composed three interceptors on method_missing. No other trace
is left in Greeter, but you can peek at its ancestors to see directly the three
module builders along with their regex matchers (interceptors override
Module#inspect to show this):
Greeter.ancestors => [Greeter, #<MethodFound::Builder:0x...>, #<MethodFound::Interceptor: /\Aask_([a-zA-Z_]+)\Z/>, #<MethodFound::Interceptor: /\Ascream_([a-zA-Z_]+)\Z/>, #<MethodFound::Interceptor: /\Asay_([a-zA-Z_]+)\Z/>, Object, ...]
So when a method is called that the class does not know, it will bubble up first to the “ask” interceptor and see if it matches the regex. If it does, it will return a value; if not, it continues up to the “scream” interceptor and checks against the second regex, and so on.
Here is the result:
greeter = Greeter.new("Bob") greeter.say_hello_world #=> "Bob says: Hello world." greeter.scream_good_morning #=> "Bob screams: Good morning!!!" greeter.ask_how_do_you_do #=> "Bob asks: How do you do?"
Given this example using module builders and method_missing, here’s a
problem for you: how would you implement what we have shown above without
module builders, but with the same level of flexibility?
The first thing that happens when you take away the module builder is that you lose the home for your module state – “normal” modules have no place to put it. So those regexes and blocks in the interceptor will need to go somewhere else, and the only other natural place to put them is the including class itself.
There are problems with this, which a real-world example should make clear.
Module Builders and Encapsulation
Let’s now take everything we’ve learned so far and apply it to some real living code at the core of Ruby’s most popular application framework.
Continuing from our discussion in the last section, I want to focus here on how modules are typically used to configure state, where that state is stored, and the problems with this approach to module configuration. I hope to convince you that module builders offer a much more natural way to encapsulate this state in the place where it best belongs: in the module itself.
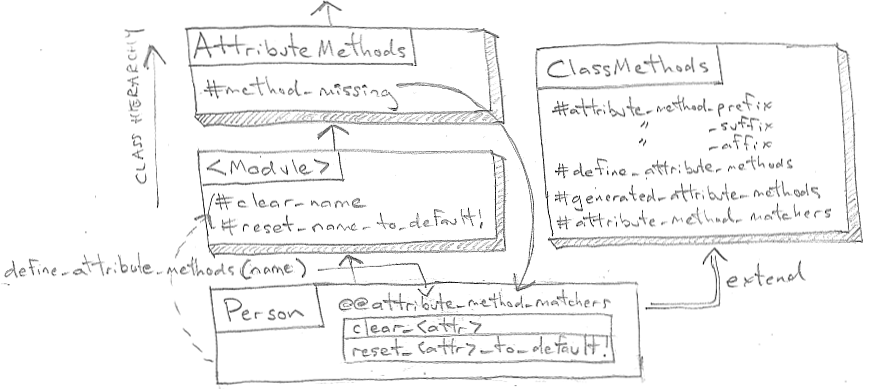
ActiveModel::AttributeMethods
The module we will look at is ActiveModel’s
AttributeMethods,
which adds support for prefixed and suffixed attribute
methods to Rails models10. If you have worked with Rails for any length
of time, you are probably familiar with these prefix/suffix patterns through
their use in change-tracking methods like name_changed? in
ActiveModel::Dirty.
The module implements both module bootstrapping (like
AdderIncluder) and message
interception using method_missing
(like MethodFound::Interceptor).
Let’s start with a simple class that implements a method prefix and a method affix:11
class Person include ActiveModel::AttributeMethods attribute_method_affix prefix: 'reset_', suffix: '_to_default!' attribute_method_prefix 'clear_' define_attribute_methods :name attr_accessor :name, :title def attributes { 'name' => @name, 'title' => @title } end private def clear_attribute(attr) send("#{attr}=", nil) end def reset_attribute_to_default!(attr) send("#{attr}=", "Default #{attr.capitalize}") end end
This is how we would use these attribute methods:
person = Person.new person.name = "foo" person.name #=> "foo" person.clear_name person.name #=> nil person.reset_name_to_default! person.name #=> "Default Name"
Just looking at the code above, it is clear that the module is storing state
somewhere, since it needs to know what prefixes, suffixes and affixes have
been defined for a given class. We can see where this state is stored in
the code for attribute_method_prefix, which is called in Person to setup a
method prefix:
def attribute_method_prefix(*prefixes) self.attribute_method_matchers += prefixes.map! { |prefix| AttributeMethodMatcher.new prefix: prefix } undefine_attribute_methods end
So the array of prefix strings are mapped to instances of a class, AttributeMethodMatcher,
stored in an array attribute_method_matchers on the Person class.
(The affix and suffix methods are similar.)
These matchers are the module’s core configuration, and they are stored
outside the module itself.
What’s in one of these matchers? Let’s have a look at the initialize
method
of the class to get an idea:
def initialize(options = {}) @prefix, @suffix = options.fetch(:prefix, ""), options.fetch(:suffix, "") @regex = /^(?:#{Regexp.escape(@prefix)})(.*)(?:#{Regexp.escape(@suffix)})$/ @method_missing_target = "#{@prefix}attribute#{@suffix}" @method_name = "#{prefix}%s#{suffix}" end
So essentially, a matcher is two things: a prefix and suffix pair, and a regex generated from them (the rest is mostly for convenience). This internal state is used for two different but related purposes.
The first of these two purposes is important but not well-documented at all; you can
find it explained inline in a comment
here.
The purpose is to provide a way to convert a hash of keys and
values returned from an attributes method into a set of first-class
attribute methods, supporting all defined prefix, suffix and affix method
patterns. In the example above, attributes returns a hash with keys name
and title, so these become attributes that dispatch to methods like
clear_attribute and reset_attribute_to_default!.
Like MethodFound, this is implemented using method_missing: any method call
which matches a matcher regex and whose target (captured from the
regex) is a key in attributes is intercepted and dispatched to an attribute
handler.
So reset_title_to_default! is dispatched to reset_attribute_to_default!,
with the name of the attribute ("title") as its argument.
Method interception is great for an open-ended, changing hash of
attributes, but method_missing is slow as molasses. If you know what attributes
you want, it’s generally better to define the methods explicitly.
This is the second purpose of the method matchers, triggered
by calling define_attribute_methods with one or more attribute names after
setting up prefixes, suffixes and affixes: to define methods for each
combination of prefix and/or suffix on each attribute. Person defines
methods for name, so clear_name and reset_name_to_default! dispatch to
clear_attribute and reset_attribute_to_default!, respectively.
These methods are bound to an anonymous module defined and
included
in another method added to the Person class, named generated_attribute_methods. As instance methods, they take
precedence over method interception, so while both
clear_title and clear_name will return the same result, the former falls
through to method_missing, whereas the latter is handled (much more quickly)
by the attribute method.
ActiveModel's AttributeMethods
You can see the defined attribute methods if you grep the methods on an
Person instance:
person = Person.new person.methods.grep /name/ #=> [:name, :name=, :reset_name_to_default!, :clear_name, ...]
You can confirm these generated methods are defined on the module, and not somewhere else, by grabbing the module and checking its instance methods:
Person.ancestors #=> [Person, #<Module:Ox...>, ActiveModel::AttributeMethods, ...] Person.ancestors[1].instance_methods #=> [:name, :name=, :reset_name_to_default!, :clear_name]
You can also find the method_missing override described earlier
here
on ActiveModel::AttributeMethods, just after the anonymous module in the class
hierarchy.
These two implementations of attribute methods, one using method interception
with method_missing and the other using method definition, complement each
other since they are suited to different access patterns (one for a large
open-ended set of attributes, the other for a smaller fixed set of
attributes). Mobility actually uses the same approach in defining i18n
accessors.12 However, whereas AttributeMethods adds a
dozen class methods and variables, Mobility adds none, instead hiding all
state in its modules.
Let’s now look at an alternative implementation of AttributeMethods which, like Mobility, uses module builders to encapsulate state in the modules it builds.
MethodFound::AttributeMethods
This is where we bring all the ideas discussed so far together and apply them to a real application. Before jumping into more code, let’s review the elements implementing attribute methods on a class:
- a class variable (
attribute_method_matchers) holding an array of matchers for prefixes/suffixes/affixes - a method_missing override to dispatch method calls matching the
attribute matchers and the
attributeshash to handlers accordingly - an included anonymous module (
generated_attribute_methods) holding defined attribute methods
Now consider that each of these core elements is located in a different place:
- the method matchers are defined on the including class
- the generated attribute methods are defined on an anonymous module included in this class
method_missingis defined on AttributeMethods itself, also included in the class
So we have the three elements of our implementation, coupled to each other through the method matchers class variable, spread out across different parts of the implementing system. Not only that, but the method matchers and generated methods, which (as we will see below) are essentially functionally independent, are stored together in the same place (an array and an anonymous module, respectively).
Let’s consider an alternative implementation which distributes state in a different way. In this implementation, we will group the following elements together into a single module using a module builder:
- a single prefix/suffix pair, from which a matcher regex is generated
- a single
method_missingoverride which uses the regex to intercept methods - a method to define attribute methods for the given prefix/suffix pair
The module builder is named
AttributeInterceptor.
It inherits from
MethodFound::Interceptor, which we saw in the last section, customizing the
initializer so that it accepts a prefix and/or suffix instead of the more
open-ended format of the default interceptor builder. Although it is not very
big, I won’t include the actual code here so we can instead focus on what the
class actually does.
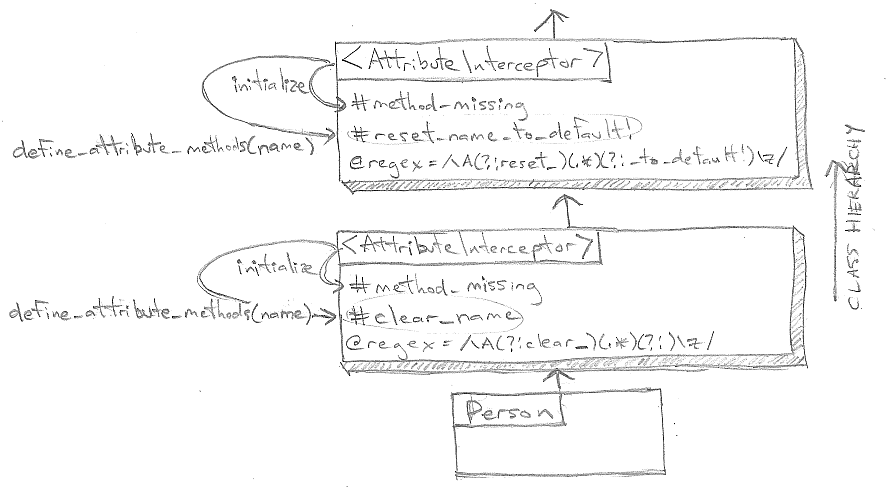
Implementing AttributeMethods with MethodFound interceptors
Let’s first take a look at intercepting. We can reproduce this by replacing
calls to define_attribute_prefix and define_attribute_affix in the
Person class above with attribute interceptors, like this:
class Person include MethodFound::AttributeInterceptor.new(prefix: 'clear_') include MethodFound::AttributeInterceptor.new(prefix: 'reset_', suffix: '_to_default!') attr_accessor :name, :title def attributes { 'name' => @name, 'title' => @title } end # ... end
We are instantiating two attribute interceptors and including each of them into the class. There is no special case here for “affix”; we simply build an interceptor with both a prefix and suffix.
With these modules included, Person behaves externally exactly the same as the earlier version
using the ActiveModel module, but the internal implementation is quite
different. This can be seen from its ancestors:
Person.ancestors #=> [Person, #<MethodFound::AttributeInterceptor: /\A(?:reset_)(.*)(?:_to_default!)\z/>, #<MethodFound::AttributeInterceptor: /\A(?:clear_)(.*)(?:)\z/>, ... ]
Like the MethodFound interceptors described earlier, these two modules
each override method_missing and branch the code path if the method name
matches their regex (stored on the module).
The resulting set of distributed nested conditionals is equivalent to this line from ActiveModel, which iterates through attribute method matchers checking for matches:
matchers.map { |method| method.match(method_name) }.compact
The key difference between these two implementations is that whereas this line
is executed in ActiveModel::AttributeMethods (a module), using a class variable
stored in Person (a class), the MethodFound version is executed across
independent modules through method composition, using super.
The implementation of generated attribute methods is similar.
AttributeInterceptor has a method define_attribute_methods which takes
one or more attribute names and defines attribute methods for each of them
with the module’s prefix and/or suffix, on the module itself. Again, because
the module already contains its own prefix and suffix, it has all the
information it needs to do this.
So functionality is truly encapsulated: a single module contains its own
prefix and suffix, the method_missing override to catch attribute method
calls, and a method to generate its own attribute method.13
Given this module builder, we can reproduce ActiveModel’s implementation without any class methods or class variables, like this:
class Person [ MethodFound::AttributeInterceptor.new(prefix: 'clear_'), MethodFound::AttributeInterceptor.new(prefix: 'reset_', suffix: '_to_default!') ].each do |mod| mod.define_attribute_methods(:name) include mod end #... end
MethodFound includes another module, MethodFound::AttributeMethods,
which adds class methods do simplify the code above, so it can be used as a
drop-in replacement for ActiveModel::AttributeMethods. The
implementation of
define_attribute_methods in this module is interesting:
def define_attribute_methods(*attr_names) ancestors.each do |ancestor| ancestor.define_attribute_methods(*attr_names) if ancestor.is_a?(AttributeInterceptor) end end
Since the class no longer stores the matchers in its state, the module cannot
simply iterate through these matchers to define methods. Instead, it iterates
through its own ancestors, which are module instances each with a
prefix/suffix pair, and calls define_attribute_methods if the ancestor is an
attribute interceptor. This generates attribute methods on each interceptor
module, which can then be called by instances of the class.
The resulting implementation encapsulates related elements together into separate modules without coupling via class variables or methods. This encapsulation means that we could now design totally different types of attribute interceptors and include them in the same way; as long as they have the same interface (for generating attribute methods), the internals can be entirely different and nothing else will need to change.
This, it seems to me, is what a “module” should really be: an independent, interchangeable unit containing everything it needs to execute only one aspect of some desired functionality. Not only that, but the interface for building these modules falls directly out of Ruby’s own object model, a model that has been around as long as the language itself. Ruby has had this trick up its sleeve for years, most of us just never realized it.
What’s in a Name?
You may argue that the “Module Builder Pattern” I’ve introduced is just a Ruby
subclass where the class happens to be Module, and what’s the big deal? And
technically, you would be right. I’m not the first to notice this idea, nor am
I the first to write about it. Just Foo < Module, and I could be done with it.
But programming languages are written and read by and for humans, and to humans, names mean a lot. If you can’t find the module with the methods on it buried in a list of ancestors, you won’t notice it, and if you can’t remember that subclassing thing some blogger wrote about, you won’t use it. The fact that this pattern has been around for this long without almost anybody knowing about it is testament to this fact.
So I gave it a name. A catchy one.
Because as Rubyists, I think we need this pattern. Take a look at the code of a large Ruby project and how modules are used (and abused) in practice. Our modules trigger callbacks that bootstrap all kinds of extra state into our classes, coupling them to the modules they include. A module should be self-contained, but we use the excuse that we cannot configure modules at runtime to justify storing configuration all over the place.
Ruby can do better than this, and we can do better than this. So take another look at that bloated module, the one with the tentacles that seem to have crept over every corner of your application, and give it a chance to be free. I think you will find that it — and you — will be all the better for it.
Update (2017/10/20)
This post has been translated into Japanese: see part 1, part 2 and part 3.
Update (2017/09/27)
Since writing this blog post, I have also presented the Module Builder Pattern at RubyKaigi 2017 in Hiroshima. Slides from that talk can be found on Speaker Deck, and a video has also been posted to YouTube.
Notes
1 The first reference I can find to the
idea of “subclassing Module” is in an article in
2012
by Piotr Solnica. Eric
Anderson and Andreas
Robecke have written about it more
recently, but hardly anything else even mentions it.
2 At the time of writing this post, it
is used
here
and
here.
3 By this I mean you can include
modules on over another and use super to build complex composed method
chains. I do a lot of this in Mobility.
4 And, to be precise, which also has an
initializer which takes the values of these attributes as its
arguments.
5 I’ve used a trick here to add a
module’s methods as class methods to a class using include, by extending the
class when the module is included. This is a common trick, if it looks a bit
mysterious you might want to read up on the technique before
continuing.
6 This “no-clutter” property of
anonymous modules is also what makes them so handy in metaprogramming, since
it means you don’t need to worry about constant name collisions.
7 It is actually being defined from
these keys using a
closure.
8 Defining an inspect method in
the module builder class which includes the variables (e.g. amount and
tax) which define makes this ancestor chain even easier to
read.
9 MethodFound actually does a bit more
than this: it also “caches” the method name matched in the regex or proc and
defines it on the interceptor module, so that future calls will be much
faster. You can see this if you look at the methods on an interceptor after it
has matched a method using method_missing.
10 ActiveRecord models in fact include
ActiveRecord::AttributeMethods, which itself includes
ActiveModel::AttributeMethods and overrides some of the methods discussed
here, specifically define_attribute_methods. The relationship between these
two modules, and between how persisted and non-persisted attribute methods are
handled, is somewhat complex, but the ideas discussed here are relevant to
both.
11 Note that I have slightly modified
and simplified this example class from the one in the inline documentation to
highlight some things that the standard docs do not mention.
12 Mobility handles these two cases
with the module builders FallthroughAccessors and
LocaleAccessors. I also extracted these from Mobility into a gem called
I18nAccessors.
13 It actually also has a method
alias_attribute to alias attributes, like
ActiveModel::AttributeMethods.
Figures
a “Drawing Hands” by M.C. Escher.
[reference]
b “Automated space exploration and
industrialization using self-replicating systems.” From Advanced Automation
for Space Missions: 5. REPLICATING SYSTEMS CONCEPTS: SELF-REPLICATING LUNAR
FACTORY AND DEMONSTRATION.
[reference]
c “Proposed demonstration of simple
robot self-replication.”
[reference]